
○robots.txt の概要
自分がスクレイピングしたい記事が許可されているのか禁止されているのかはそのサイトのURLの末尾に「/robots.txt」と入力して、検索すると調べることができます。私のサイトだと以下のようになります。

User-agent:
→どのクロールを制御するかを指定する。
「*」→全てのクロールが対象。
Allow:
→クロールが許可されているもの。
「Allow: 」→「Disallow:」で指定されているサイトを除いて、すべてのページにアクセスできる。
「Allow: / 」→上の空白と同様。
Disallow:
→クロールが許可されていないもの。
「Disallow: 」→すべてのページにアクセスできない。
「Disallow: / 」→上の空白と同様。
Sitemap:
→クロールして欲しいURLを列挙するXMLファイル。
Crawl-delay:
→クロールする間隔(秒)
Sitemap:
→巡回してほしいURLをクローラーに伝えることができる。
参考サイト
○robots.txtとは?作り方・書き方・確認方法を解説します
○robots.txtとは?意味から設定方法まで詳しく解説
○Python でクローリング、スクレイピングする前に確認しておきたいこと
○スクレイピング、クローリングする時の注意点
「robotx.txt の内容に従いましょう」とよく言うけど・・・
自分が知らない間に、スクレイピングが禁止され、スクレイピングしてしまうという違反は誰でも犯したくないはずです。なので、「urlib.robotparser」を使用して、「robots.txt」を解析し、スクレイビングが許可されていれば、スクレイビングするようなプログラムを構築していきます。以下のサイトを参考にしました。
○Python-urllib.robotparser による robots.txt の解析
○13.3. robotparser — Parser for robots.txt
はじめに「RobotFileParser」をインポートします。分析したいサイトを変数urlに入れています。
インスタンスを作成し、set_url()メソッドで”分析したいURL”を設定します。”分析したいURL”の末尾は「robots.txt」canになります。can_fetchメソッドを使用して、スクレイピングが許可されているかどうかを調べます。スクレイピングが許可されていれば、「Ture」、許可されていなければ、「False」が実行結果で表示されます。完成したコードは以下のようになります。
from urllib.robotparser import RobotFileParser
url = "分析したいURL"
rp = RobotFileParser()
rp.set_url(url)
rp.read()
print(rp.can_fetch("*","スクレイピングが許可されているのか調べたいURL"))
はじめに、私のブログで禁止されている部分を試しに分析させてみます。
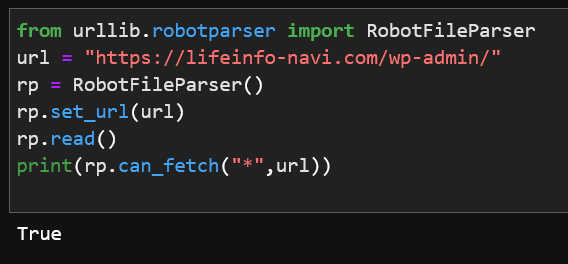
スクレイピングが禁止されているのに、「Ture」と表示されてしまいます。クッキーなどの問題かなと思いましたが、ワードプレスで作られているサイト全てがスクレイピングが禁止されてURLで上記を実行しても、「Ture」で表示されるようです。(私だけかもしれませんが)
Amazonで禁止されているURLを解析させると「False」と表示されるので、ワードプレス以外のサイトではスクレイピングができるかどうかの判断を「RobotFileParser」に判断してもらうことにします。
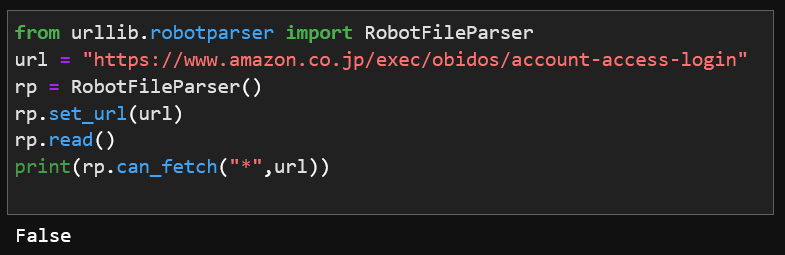
*おそらく上記の記述方法を正しくありません。set_url()メソッドには末尾に「robots.txt」のURL、can_fetch()メソッドにはスクレイピングが許可されているのか調べたいURLを記述します。正しくは以下のような記述になると思います。
import re
from urllib.robotparser import RobotFileParser
url = "https://lifeinfo-navi.com/p=1987"
pattern = "https?://[^/]+/"
r = re.match(pattern,url)
rp = RobotFileParser()
rp.set_url(r.group()+"robots.txt")
rp.read()
print(rp.can_fetch("*",url))
これで「RobotFileParser」によりスクレイピングの許可の有無を調べることができます。
しかし、一つ問題があります。
「yahooファイナンス」はスクレイピングが禁止されていることで有名ですが、「https://profile.yahoo.co.jp/robots.txt」でロボットテキストを調べても、スクレイピングを禁止していることはわかりません。その証拠に以下のように、RobotFileParserで調べてもTrueがかえってきます。

ですので、スクレイピングをする際は利用規約を確認しなければなりません。利用規約に「スクレイピング禁止」となっているのにスクレイピングをしてしまうと違反になってしまうからです。
今のところは「調べたいサイト名」+「規約」などで検索をかけて規約内容を確認したいと思います。
スクレイピングが禁止されていて、自分が同意していないサイトでスクレイピングしてしまった場合、即刻逮捕になる可能性は低いと思いますが、警告の通知が来たりするのは嫌ですから、クロールをするサイトは事前にしっかりと利用規約を確認する必要があると思います。
なので、結局スクレイピングが許可されているのかどうかを調べるには手間がかかってしまいます。
今のところは、以下のコードを実行して、スクレイピングについての規約を調べたいと思っています。
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.google.co.jp/")
time.sleep(1)
serach_word = "サイト名 規約"
search_bar = driver.find_element_by_name("q")
serach_bar.send_keys(search_word)
time.sleep(1)
serch_bar.submit()