

目的
以下のサイトから株価のデータを取得し、GspreadSheetに入力したい。
○株式投資メモ 1305 ダイワ
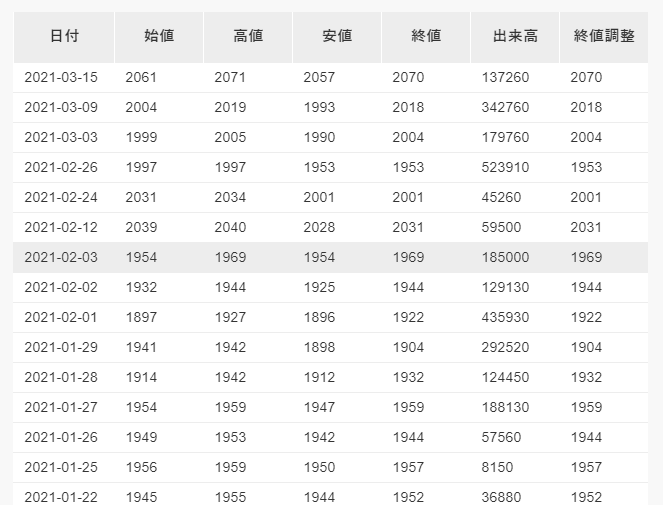
*完成コードは最後に表示しています。
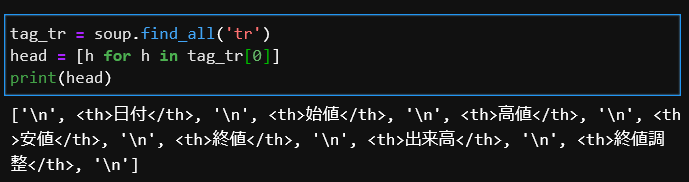
tableのheadを取得する
tag_tr = soup.find_all('tr')
head = [h.text for h in tag_tr[0].find_all('th')]<thead>は「table header」の略で、表の水平方向をグループ化するタグになります。
○theadタグとは|コーディングのプロが作るHTMLタグ辞典
<tr>は「table row」の略で表の行部分(横方向)を指定するタグです。
○trタグとは|コーディングのプロが作るHTMLタグ辞典
tag_tr = soup.find_all(‘tr’)
全てのtrタグを取得し、変数tag_trに格納しています。
head = [h.text for h in tag_tr[0].find_all(‘th’)]
内包表記で変数headにthタグの文字列がリスト化されています。tag_tr[0]には「\n」の改行文字も含まれており、find_all(“th”)でthタグだけを抜き出す必要があるようです。
テーブルの各データを取得する。
data = []
for i in range(1,len(tag_tr)):
data.append([d.text for d in tag_tr[i].find_all('td')])はじめに、空のデータリスト(data)を作成します。len(tag_tr)でbeautifulsoupで取得したtrタグの数を表します。つまり、1~trタグの数だけ繰り返し処理するということになります。append()メソッドにより()内をリストに追加することができます。
完成コード
import pandas as pd
from bs4 import BeautifulSoup
import requests
import time
headers = {"User-Agent":""}
url = "https://kabuoji3.com/stock/1305/"
res = requests.get(url,headers=headers,timeout=3)
time.sleep(3)
res.status_code
res.raise_for_status()
soup = BeautifulSoup(res.text,"html.parser")
time.sleep(2)
tag_tr = soup.find_all('tr')
head = [h.text for h in tag_tr[0].find_all("th")]
print(head)
data = []
for i in range(1,len(tag_tr)):
data.append([d.text for d in tag_tr[i].find_all('td')])
import gspread
import json
from oauth2client.service_account import ServiceAccountCredentials
def connect_gspread(jsonf,key):
scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive']
credentials = ServiceAccountCredentials.from_json_keyfile_name(jsonf, scope)
gc = gspread.authorize(credentials)
SPREADSHEET_KEY = key
worksheet = gc.open_by_key(SPREADSHEET_KEY).sheet1
return worksheet
jsonf = ".json"
spread_sheet_key = ""
sh = connect_gspread(jsonf,spread_sheet_key)
df = pd.DataFrame(data,columns = head)
sh.update([df.columns.values.tolist()] + df.values.tolist())