スクレイピングしたデータを解析したいとき、数値のみを抽出したいことがよくあります。
例えば以下のサイトでFG(フィールドゴール)の確率を取り出したいと思います。
〇シュートの「確率」を知っておけばNBAが200倍よく解る

import time
from bs4 import BeautifulSoup
import requests
headers = {"任意の値"}
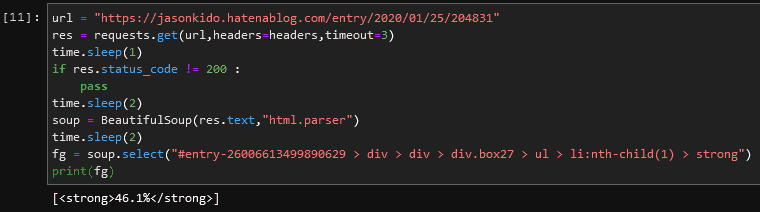
url = "https://jasonkido.hatenablog.com/entry/2020/01/25/204831"
res = requests.get(url,headers=headers,timeout=3)
time.sleep(1)
if res.status_code != 200 :
pass
time.sleep(2)
soup = BeautifulSoup(res.text,"html.parser")
time.sleep(2)
fg = soup.select("#entry-26006613499890629 > div > div > div.box27 > ul > li:nth-child(1) > strong")
print(fg)
すると以下のように抽出することができます。
これではまだタグが付いているので、「print(fg[0].string)」と記述して、FGのパーセンテージのみを取りだすことができました。

しかし、これではまだ、数値のみを抽出させることができていません。
数値のみを取り出すのはどのような方法があるのでしょうか。
調べた結果、「正規表現」や「split()」によって取り出すことができます。
split() による分割
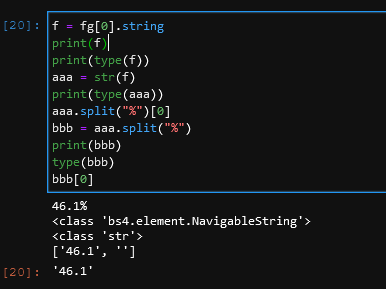
f = fg[0].string
print(f)
print(type(f))
aaa = str(f)
print(type(aaa))
aaa.split("%")
bbb = aaa.split("%")
print(bbb)
type(bbb)
bbb[0]
「split()」は文字列専用の関数になるので、4行目で変数のstr型に変更しています。 「split()」 で分割した文字列はリスト型になるので、リスト番号を指定して、分割したものを抽出します。
正規表現
〇図解!Python 正規表現の徹底解説!(文字列の抽出と置換など)
sub関数を使用する。
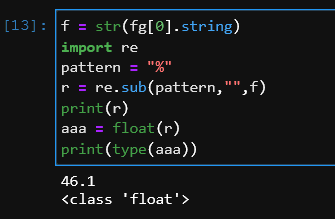
re.sub(正規表現のパターン, 置換後の文字列, 検索対象の文字列)ですので、置換後の文字列を空白にしておけば、patternで見つけ出した文字列を消去することが可能です。
search関数を使用する。
先頭に限らずパターンに一致するものがあるかを抽出する。
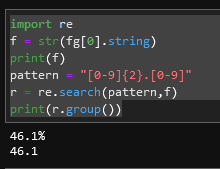
import re
f = str(fg[0].string)
print(f)
pattern = "[0-9]{2}.[0-9]"
r = re.search(pattern,f)
print(r.group())